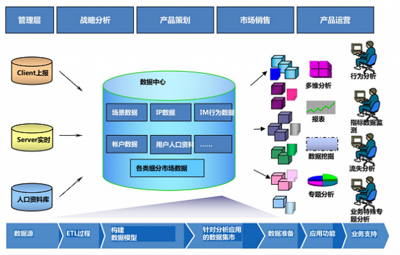
在數字化產品競爭日益激烈的今天,構建一套高效、可靠的數據運營體系已成為企業提升產品力、優化用戶體驗、驅動業務增長的核心引擎。騰訊、YY語音和迅雷等互聯網巨頭,憑借其豐富的產品矩陣和海量用戶實踐,在數據處理與存儲服務領域積累了寶貴的經驗。本文將梳理并解讀其共同踐行的11步關鍵路徑,為構建穩健的產品數據運營體系提供實戰參考。
第一步:明確數據戰略與業務目標對齊
數據運營不是無源之水。騰訊強調,數據體系構建之初,必須與公司及產品的核心戰略、關鍵業務目標(如用戶增長、活躍度、營收提升)緊密對齊。YY語音在初期便明確了通過數據分析驅動社區生態繁榮和主播變現的目標,使數據收集、處理有的放矢。
第二步:規劃全域數據采集與埋點體系
全面、準確、規范的數據是基礎。迅雷在下載業務中,建立了覆蓋用戶端、服務端、業務日志的全方位埋點體系,確保關鍵用戶行為、性能指標、業務狀態無一遺漏。騰訊則推行統一的埋點規范與管理平臺,保障數據口徑一致,減少后續治理成本。
第三步:構建彈性可擴展的數據接入層
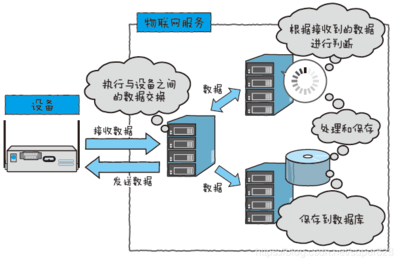
面對海量、異構、實時涌入的數據流,需要強大的接入能力。YY語音采用高可用的消息隊列(如Kafka集群)作為數據總線,實現業務數據與日志數據的異步、緩沖接入,應對峰值流量,確保數據不丟失。
第四步:設計分層分域的數據存儲架構
根據數據熱度、使用場景和成本,選擇差異化存儲方案。通用實踐是構建“原始數據層-明細數據層-匯總數據層-應用數據層”的梯級存儲。騰訊將實時熱數據存入高速NoSQL(如Redis),明細數據入分布式數據倉庫(如Hive/HDFS),聚合結果與維度表入關系型數據庫或OLAP引擎(如ClickHouse),兼顧性能與深度分析。
第五步:實施高效可靠的數據處理與計算
數據處理包括離線批處理與實時流處理。迅雷利用Hadoop/Spark生態進行大規模的離線ETL(提取、轉換、加載),清洗、關聯原始數據,生成規整的數據集市。對于實時監控和即時反饋場景(如推薦、風控),采用Flink等流計算框架進行低延遲處理,YY語音在實時互動場景中便深度依賴于此。
第六步:建立統一的數據資產管理與治理
數據成為資產,必須有效管理。騰訊數據中臺的核心之一是數據資產地圖,對數據表、指標、標簽進行全域血緣追蹤、質量監控和權限管控。建立數據標準、保障數據安全與合規(如GDPR),是可持續運營的基石。
第七步:搭建敏捷的數據服務與API化
將數據能力以服務形式開放,賦能業務。通過構建統一的數據服務層,將復雜的查詢、模型計算結果封裝成標準API,供產品端、運營后臺、分析系統調用。迅雷和YY語音都通過API網關,高效、安全地向內部各團隊提供用戶畫像、行為分析等數據服務。
第八步:部署智能化的數據分析與挖掘平臺
為分析師和業務人員提供自助分析工具(如BI平臺),降低數據使用門檻。搭建機器學習平臺,支持特征工程、模型訓練與部署,實現從描述性分析到預測性、指導性分析的飛躍。騰訊在此領域投入巨大,以支撐其精準營銷和內容推薦等智能業務。
第九步:實現產品端的實時反饋與個性化應用
數據價值最終體現在產品端。通過將處理后的數據、用戶標簽、模型評分實時反饋給產品客戶端或推薦引擎,實現千人千面的內容分發、個性化提示、智能客服等,直接提升用戶體驗和轉化率,這是YY語音運營直播房間、騰訊運營內容生態的關鍵環節。
第十步:建立閉環的數據驅動決策與運營流程
將數據分析洞察融入產品迭代和運營活動全生命周期。通過A/B測試平臺驗證想法,監控核心數據看板評估效果,形成“假設-實驗-分析-迭代”的閉環。迅雷在下載加速策略優化中,便嚴格遵循這一數據驅動的實驗文化。
第十一步:持續監控、優化與成本效能評估
數據體系需要持續運營和維護。監控數據管道健康度、任務時效、存儲與計算資源消耗。在保障穩定性的通過技術優化(如數據壓縮、計算資源調度、冷熱數據分離)和架構演進,不斷平衡成本、性能與業務價值,確保數據運營體系長期高效、經濟地運轉。
****
構建產品數據運營體系是一項系統工程,上述11步環環相扣,從頂層設計到底層技術,從數據生產到價值消費。騰訊、YY語音和迅雷的實踐表明,成功的體系源于技術與業務的深度融合,以及持續迭代的運營思維。關鍵在于以業務價值為導向,以可靠的數據處理與存儲服務為基石,最終打造出能夠敏銳感知用戶、快速響應市場、智能驅動增長的強大數據引擎。