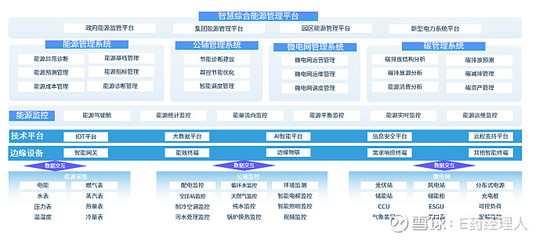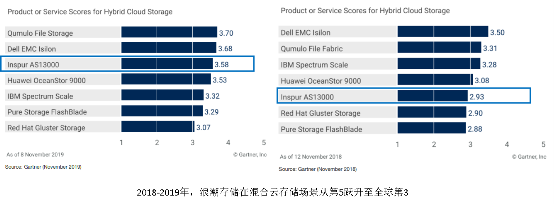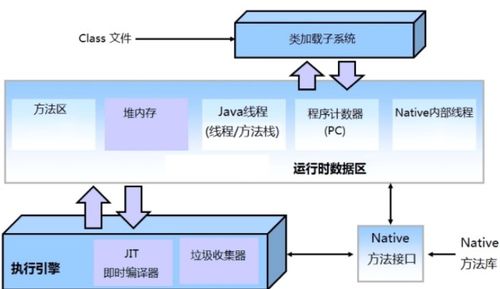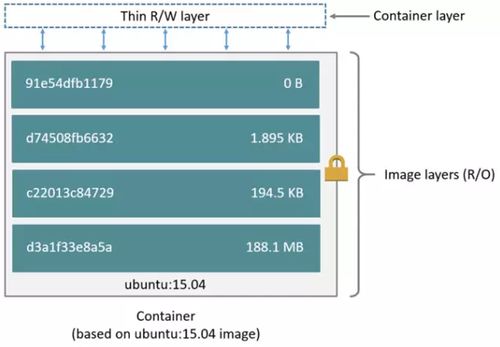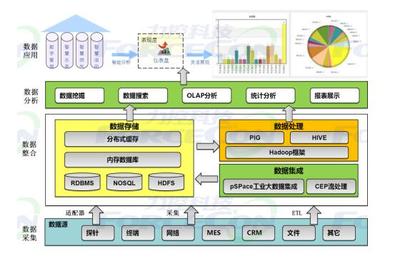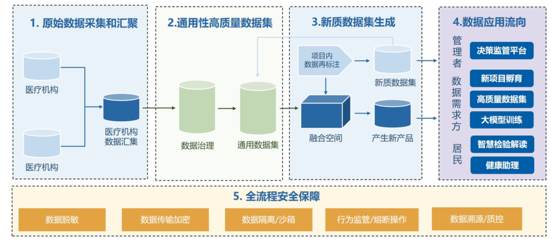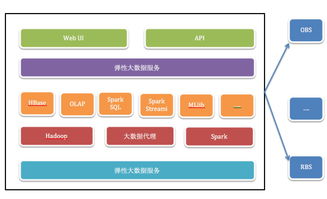
隨著云計算、大數據、人工智能和物聯網技術的迅猛發展,數據已從靜態的資源演變為驅動創新的核心動能。傳統集中式數據庫在處理海量、高并發、多源異構數據時,日益暴露出擴展性、可用性和成本效率的瓶頸。分布式數據庫的崛起,常被簡單視為對傳統數據庫的“替換”或“升級”。其真正的價值與愿景,遠比“替換”二字宏大深邃——它正引領我們駛向數據處理與存儲服務的“星辰大海”,構建一個更加彈性、智能和普惠的數據基礎設施新時代。
一、超越替換:從架構革新到服務范式重構
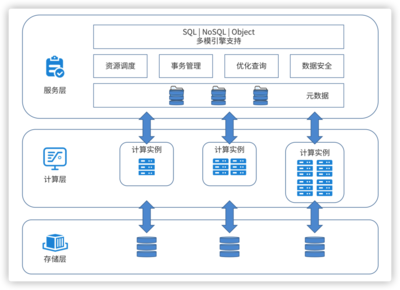
分布式數據庫的核心突破并非僅是技術棧的簡單更迭。它通過將數據分布存儲和處理在多個物理或虛擬節點上,實現了:
- 無限水平擴展:通過添加節點即可線性提升存儲容量與計算能力,從容應對數據量的指數級增長。
- 高可用與強韌性:多副本機制和智能故障轉移確保服務“永遠在線”,滿足關鍵業務對連續性的嚴苛要求。
- 地理級分布與低延遲:數據可就近部署于全球邊緣,為跨地域應用提供一致的毫秒級訪問體驗。
這標志著從“以數據庫為中心”到“以數據服務為中心”的根本性轉變。數據庫不再是一個孤立的軟件產品,而是演化為可彈性供給、按需組合的云原生數據服務層。
二、數據處理新境界:實時、智能與融合
分布式數據庫的“星辰大海”,在于它如何重新定義數據處理本身:
- 實時分析與決策:借助內存計算、流處理引擎與分布式架構的深度融合,實現海量數據的實時查詢、分析與洞察,讓業務決策從“事后回顧”走向“當下行動”。
- AI-Native智能化:數據庫內原生集成機器學習框架,支持模型訓練與推理,實現數據的“在庫智能”,簡化AI應用開發流程,提升效率。
- 多模數據融合處理:統一平臺支持關系、文檔、圖、時序、KV等多種數據模型,打破“一種數據庫對應一種場景”的藩籬,簡化技術棧,釋放多源數據的關聯價值。
三、存儲服務新范式:成本、安全與主權
在存儲層面,分布式數據庫同樣開辟了新航道:
- 精細化成本優化:通過存算分離架構、冷熱數據分層(如與對象存儲無縫集成)、數據壓縮與編碼技術,實現存儲成本的量級下降與極致優化。
- 內生安全與隱私增強:將加密計算(如全同態加密)、差分隱私、細粒度訪問控制等能力內置于數據存儲與處理的各個環節,構建“默認安全”的數據環境。
- 數據主權與合規支撐:憑借靈活的地理分布能力,可輕松滿足不同地區的數據駐留(Data Residency)和隱私保護法規(如GDPR)要求,為全球業務鋪平道路。
四、賦能未來應用:云邊端一體與行業重塑
分布式數據庫的能力邊界正不斷拓展,成為未來創新應用的基石:
- 支撐云邊端一體化協同:作為統一的數據層,連接云端智能與邊緣實時響應,為工業互聯網、智慧城市、自動駕駛等場景提供堅實的數據底座。
- 驅動行業數字化轉型:在金融、電信、政務、零售、醫療等領域,不僅支撐核心系統現代化,更催生出基于實時數據流的全新業務模式與服務體驗。
- 激發開發者創造力:通過提供Serverless、全球分布式、多模型接口等易用服務,降低開發復雜度,讓開發者更專注于業務創新本身。
分布式數據庫的征程,絕非一場簡單的技術替代。它是一場深刻的數據基礎設施革命,其“星辰大海”在于重新定義數據如何被存儲、處理、賦能并最終創造價值。從構建彈性可擴展的全球數據平面,到實現實時智能的數據處理,再到保障安全合規的精細化數據治理,分布式數據庫正在繪制一幅數據處理與存儲服務全景式升級的宏偉藍圖。未來已來,這片廣闊的“星辰大海”正等待我們揚帆遠航,去探索、去構建一個由數據驅動的無限可能的新世界。